Background When we use groupBy, it generates a single value from every group.
If we not only want to operate on a group of rows but also want our function return a single value for every input row, we should use window function.
Example of last_activity_time Business requirement We have a user table with 3 columns. When user click our app, our tracking application will save user’s tracking record. For example: user Tom used its Linux device visited our website at 1st day, then uses ios device visited on 2nd and 3rd days.
user_name
active_timestamp
os
Tom
1
linux
Tom
2
ios
Tom
3
ios
Speike
3
windows
Speike
4
ios
Speike
5
ios
Jerry
6
android
Jerry
7
ios
Jerry
8
windows
Jerry
9
linux
Jerry
10
macbook
Our requirement is to calculate the last active timestamp of Tom, Jerry and Speike.
Implementation Prepare for data 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def prepareExampleData DataFrame = { val columns = Seq ("user_name" , "activity_time" , "os" ) val data = Seq ( ("Tom" , 1 , "linux" ), ("Tom" , 2 , "ios" ), ("Tom" , 3 , "ios" ), ("Speike" , 3 , "windows" ), ("Speike" , 4 , "ios" ), ("Speike" , 5 , "ios" ), ("Jerry" , 6 , "android" ), ("Jerry" , 7 , "ios" ), ("Jerry" , 8 , "windows" ), ("Jerry" , 9 , "linux" ), ("Jerry" , 10 , "macbook" ) ) spark.createDataFrame(data).toDF(columns: _*) }
Use Spark SQL 1 2 3 4 5 6 7 8 9 10 def calculateLastActivitySql DataFrame => DataFrame = { df => df.createTempView("user_table" ) df.sqlContext.sql( """ |select *, |first(activity_time) over(partition by user_name order by activity_time desc) as last_activity_time |from user_table""" .stripMargin ) }
Use Spark DataFrame API 1 2 3 4 5 def calculateLastActivity DataFrame => DataFrame = { df => val window = Window .partitionBy("user_name" ).orderBy(col("activity_time" ).desc) df.withColumn("last_activity_time" , first("activity_time" ).over(window)) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 +---------+-------------+-------+------------------+ |user_name|activity_time| os|last_activity_time| +---------+-------------+-------+------------------+ | Tom| 3| ios| 3| | Tom| 2| ios| 3| | Tom| 1| linux| 3| | Jerry| 10|macbook| 10| | Jerry| 9| linux| 10| | Jerry| 8|windows| 10| | Jerry| 7| ios| 10| | Jerry| 6|android| 10| | Speike| 5| ios| 5| | Speike| 4| ios| 5| | Speike| 3|windows| 5| +---------+-------------+-------+------------------+
Compare with groupBy 1 2 3 4 5 6 7 8 def compareWithGroupby DataFrame => DataFrame = { df => val result = df.groupBy("user_name" ).agg( max("activity_time" ).as("last_activity_time" ) ) df.join(result, usingColumn = "user_name" ) .select("user_name" , "activity_time" , "os" , "last_activity_time" ) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 == Physical Plan == *(3 ) Project [user_name#6 , activity_time#7 , os#8 , last_activity_time#16 ] +- *(3 ) BroadcastHashJoin [user_name#6 ], [user_name#19 ], Inner , BuildRight :- LocalTableScan [user_name#6 , activity_time#7 , os#8 ] +- BroadcastExchange HashedRelationBroadcastMode (List (input[0 , string, true ])) +- *(2 ) HashAggregate (keys=[user_name#19 ], functions=[max(activity_time#20 )]) +- Exchange hashpartitioning(user_name#19 , 200 ) +- *(1 ) HashAggregate (keys=[user_name#19 ], functions=[partial_max(activity_time#20 )]) +- LocalTableScan [user_name#19 , activity_time#20 ] == Physical Plan == Window [first(activity_time#7 , false ) windowspecdefinition(user_name#6 , activity_time#7 DESC NULLS LAST , specifiedwindowframe(RangeFrame , unboundedpreceding$(), currentrow$())) AS last_activity_time#34 ], [user_name#6 ], [activity_time#7 DESC NULLS LAST ]+- *(1 ) Sort [user_name#6 ASC NULLS FIRST , activity_time#7 DESC NULLS LAST ], false , 0 +- Exchange hashpartitioning(user_name#6 , 200 ) +- LocalTableScan [user_name#6 , activity_time#7 , os#8 ]
Conditioned window implementation Now we have another requirement: calculate the last_ios_active_time.
last_ios_active_time represents the last time that user uses its ios platform.
For example, Jerry uses ios to login our website at 7th day while he uses Windows device on 8th day. So Jerry’s last_ios_activity_time is 7.
user_name
active_timestamp
os
last_ios_active_time
Tom
1
linux
Tom
2
ios
Tom
3
ios
3
Speike
3
windows
Speike
4
ios
Speike
5
ios
5
Jerry
6
android
Jerry
7
ios
7
Jerry
8
windows
Jerry
9
linux
Jerry
10
macbook
If we want to calculate this metric, we should have a window with a condition: only consider the record that os = “ios”.
To implement this, we can duplicate a temporary column for window.
user_name
active_timestamp
os
_tmp_window_order_timestamp
Tom
1
linux
null
Tom
2
ios
2
Tom
3
ios
3
Speike
3
windows
null
Speike
4
ios
4
Speike
5
ios
5
Jerry
6
android
null
Jerry
7
ios
7
Jerry
8
windows
null
Jerry
9
linux
null
Jerry
10
macbook
null
And then set a window order by this temporary timestamp.
1 2 3 4 5 6 7 8 9 10 def calcLastIosActivityTime String = "_tmp_window_order_timestamp" ) : DataFrame => DataFrame = { df => { val conditionedDf = df.withColumn(tmp_col_name, when(col("os" ) === "ios" , col("activity_time" )).otherwise(null )) val conditionedWindow = Window .partitionBy("user_name" ).orderBy(col(tmp_col_name).desc) conditionedDf.withColumn("last_ios_active_time" , first(tmp_col_name).over(conditionedWindow)) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 +---------+-------------+-------+---------------------------+--------------------+ |user_name|activity_time| os|_tmp_window_order_timestamp|last_ios_active_time| +---------+-------------+-------+---------------------------+--------------------+ | Tom| 3| ios| 3| 3| | Tom| 2| ios| 2| 3| | Tom| 1| linux| null| 3| | Jerry| 7| ios| 7| 7| | Jerry| 6|android| null| 7| | Jerry| 8|windows| null| 7| | Jerry| 9| linux| null| 7| | Jerry| 10|macbook| null| 7| | Speike| 5| ios| 5| 5| | Speike| 4| ios| 4| 5| | Speike| 3|windows| null| 5| +---------+-------------+-------+---------------------------+--------------------+
Boundary Sometimes we may add some redundant orderBy command. It supports to be no effect.
But actually, in some cases, redundant orderBy may lead the unexpected problem.
Our business requirement is to calculate last_ios_activity_time. We have two methods to calculate this metric.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private def showWindowBoundary val df = prepareExampleData val tmp_col_name: String = "_tmp_window_order_timestamp" val conditionedDf = df.withColumn(tmp_col_name, when(col("os" ) === "ios" , col("activity_time" )).otherwise(null )).cache() println("Method 1" ) val boundaryWindow = Window .partitionBy("user_name" ).orderBy(col("activity_time" ).desc) conditionedDf.withColumn("last_ios_active_time" , max(tmp_col_name).over(boundaryWindow)).show() println("Method 2" ) val userWindow = Window .partitionBy("user_name" ) conditionedDf.withColumn("last_ios_active_time" , max(tmp_col_name).over(userWindow)).show() }
Method 1 has a redundant orderBy(col("activity_time").desc) since we finally use max to calculate the metric. While Method 2 doesn’t have any orderBy.
It seems that the redundant orderBy won’t affect anything. But finally we find it will lead to some record in partition cannot be covered by the Window calculation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Method 1 +---------+-------------+-------+---------------------------+--------------------+ |user_name|activity_time| os|_tmp_window_order_timestamp|last_ios_active_time| +---------+-------------+-------+---------------------------+--------------------+ | Tom| 3| ios| 3| 3| | Tom| 2| ios| 2| 3| | Tom| 1| linux| null| 3| | Jerry| 10|macbook| null| null| | Jerry| 9| linux| null| null| | Jerry| 8|windows| null| null| | Jerry| 7| ios| 7| 7| | Jerry| 6|android| null| 7| | Speike| 5| ios| 5| 5| | Speike| 4| ios| 4| 5| | Speike| 3|windows| null| 5| +---------+-------------+-------+---------------------------+--------------------+
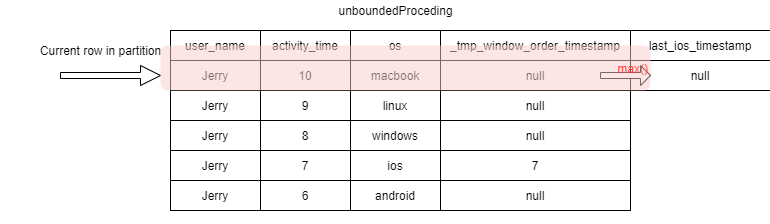
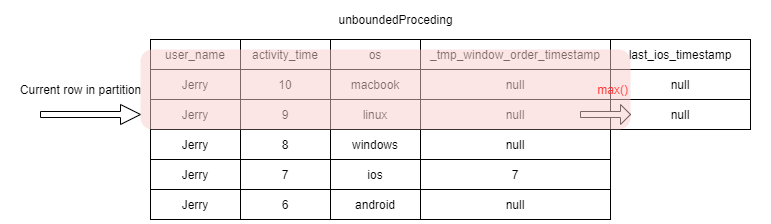
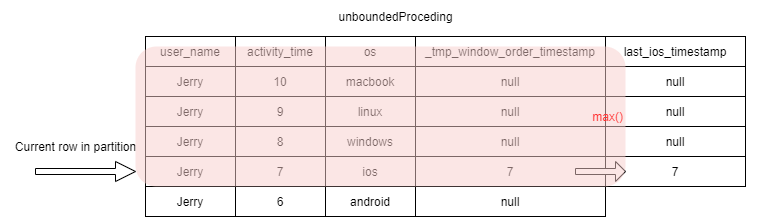
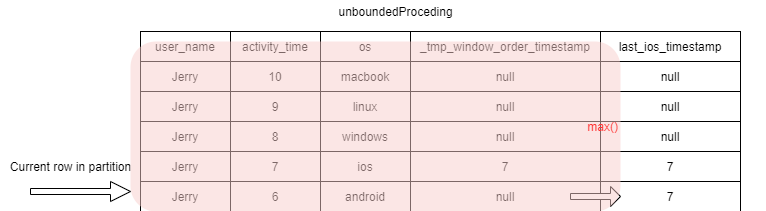
From the data we can see that Jerry uses his ios on 7th day, which is the latest activity_time.
If we order all Jerry’s tracking data by activity time descending, there is 3 records before the record that user_name=Jerry and active_timestamp=7.
This means if our Window’s spec is from the current row to the first row, the record with activity_time=8 to 10 will not be covered.
Method 2 calculated normal value.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Method 2 +---------+-------------+-------+---------------------------+--------------------+ |user_name|activity_time| os|_tmp_window_order_timestamp|last_ios_active_time| +---------+-------------+-------+---------------------------+--------------------+ | Tom| 1| linux| null| 3| | Tom| 2| ios| 2| 3| | Tom| 3| ios| 3| 3| | Jerry| 6|android| null| 7| | Jerry| 7| ios| 7| 7| | Jerry| 8|windows| null| 7| | Jerry| 9| linux| null| 7| | Jerry| 10|macbook| null| 7| | Speike| 3|windows| null| 5| | Speike| 4| ios| 4| 5| | Speike| 5| ios| 5| 5| +---------+-------------+-------+---------------------------+--------------------+
Why null still occurs We can see the logical plan. When we use orderBy, the default spec is unboundedpreceding to current row.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 conditionedDf.withColumn("last_ios_active_time" , max(tmp_col_name).over(boundaryWindow)).explain(true ) == Parsed Logical Plan == 'Project [user_name#6 , activity_time#7 , os#8 , _tmp_window_order_timestamp#22 , max('_tmp_window_order_timestamp ) windowspecdefinition('user_name , 'activity_time DESC NULLS LAST , unspecifiedframe$()) AS last_ios_active_time#291 ]+- Project [user_name#6 , activity_time#7 , os#8 , CASE WHEN (os#8 = ios) THEN activity_time#7 ELSE cast(null as int) END AS _tmp_window_order_timestamp#22 ] +- Project [_1#0 AS user_name#6 , _2#1 AS activity_time#7 , _3#2 AS os#8 ] +- LocalRelation [_1#0 , _2#1 , _3#2 ] == Analyzed Logical Plan == user_name: string, activity_time: int, os: string, _tmp_window_order_timestamp: int, last_ios_active_time: int Project [user_name#6 , activity_time#7 , os#8 , _tmp_window_order_timestamp#22 , last_ios_active_time#291 ]+- Project [user_name#6 , activity_time#7 , os#8 , _tmp_window_order_timestamp#22 , last_ios_active_time#291 , last_ios_active_time#291 ] +- Window [max(_tmp_window_order_timestamp#22 ) windowspecdefinition(user_name#6 , activity_time#7 DESC NULLS LAST , specifiedwindowframe(RangeFrame , unboundedpreceding$(), currentrow$())) AS last_ios_active_time#291 ], [user_name#6 ], [activity_time#7 DESC NULLS LAST ] +- Project [user_name#6 , activity_time#7 , os#8 , _tmp_window_order_timestamp#22 ] +- Project [user_name#6 , activity_time#7 , os#8 , CASE WHEN (os#8 = ios) THEN activity_time#7 ELSE cast(null as int) END AS _tmp_window_order_timestamp#22 ] +- Project [_1#0 AS user_name#6 , _2#1 AS activity_time#7 , _3#2 AS os#8 ] +- LocalRelation [_1#0 , _2#1 , _3#2 ]
When we don’t use orderBy, the default spec is unboundedproceding, unboundedfollowing.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 conditionedDf.withColumn("last_ios_active_time" , max(tmp_col_name).over(userWindow)).explain == Parsed Logical Plan == 'Project [user_name#865 , activity_time#866 , os#867 , _tmp_window_order_timestamp#871 , max('_tmp_window_order_timestamp ) windowspecdefinition('user_name , unspecifiedframe$()) AS last_ios_active_time#1383 ]+- Project [user_name#865 , activity_time#866 , os#867 , CASE WHEN (os#867 = ios) THEN activity_time#866 ELSE cast(null as int) END AS _tmp_window_order_timestamp#871 ] +- Project [_1#859 AS user_name#865 , _2#860 AS activity_time#866 , _3#861 AS os#867 ] +- LocalRelation [_1#859 , _2#860 , _3#861 ] == Analyzed Logical Plan == user_name: string, activity_time: int, os: string, _tmp_window_order_timestamp: int, last_ios_active_time: int Project [user_name#865 , activity_time#866 , os#867 , _tmp_window_order_timestamp#871 , last_ios_active_time#1383 ]+- Project [user_name#865 , activity_time#866 , os#867 , _tmp_window_order_timestamp#871 , last_ios_active_time#1383 , last_ios_active_time#1383 ] +- Window [max(_tmp_window_order_timestamp#871 ) windowspecdefinition(user_name#865 , specifiedwindowframe(RowFrame , unboundedpreceding$(), unboundedfollowing$())) AS last_ios_active_time#1383 ], [user_name#865 ] +- Project [user_name#865 , activity_time#866 , os#867 , _tmp_window_order_timestamp#871 ] +- Project [user_name#865 , activity_time#866 , os#867 , CASE WHEN (os#867 = ios) THEN activity_time#866 ELSE cast(null as int) END AS _tmp_window_order_timestamp#871 ] +- Project [_1#859 AS user_name#865 , _2#860 AS activity_time#866 , _3#861 AS os#867 ] +- LocalRelation [_1#859 , _2#860 , _3#861 ]
For the record with activity_time=10, its window calculation result is null.
In the second record, its window spec is from current line to the first line.
When it comes to the record with activity_time=7, the window spec includes _tmp_window_order_timestamp=7. So the max() calculation result is 7.
When it comes to the record with activity=6, its windos spec alos includes 7.
Reference docs https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
https://stackoverflow.com/questions/40048919/what-is-the-difference-between-rowsbetween-and-rangebetween
User table
Boundary